
LoRA Craft
Fine-tune large language models into specialized assistants with a web-based interface. No ML expertise required—just choose your model, dataset, and reward function.
What is LoRA Craft?
LoRA Craft is a web-based application for fine-tuning large language models using reinforcement learning. It combines GRPO (Group Relative Policy Optimization) with LoRA adapters to enable efficient training on consumer GPUs, requiring no machine learning expertise or code.
Why Choose LoRA Craft?
No-Code Training
Configure and train models through an intuitive web interface. No Python scripts, no command-line complexity—just point, click, and train.
Docker Ready
Start in minutes with Docker—no manual dependency setup required. Works on Windows (WSL2), Linux, and macOS with automatic GPU detection.
Efficient Fine-Tuning
Uses LoRA adapters to train on consumer GPUs (4-8GB VRAM). Fine-tune 7B models on your desktop with GRPO reinforcement learning.
Real-Time Monitoring
Watch your model improve with live metrics: rewards, loss, KL divergence, and more. Interactive charts show training progress as it happens.
Ready-to-Use Rewards
Choose from pre-built reward functions for math, coding, reasoning, and more. Or create custom rewards for your specific task.
See It In Action
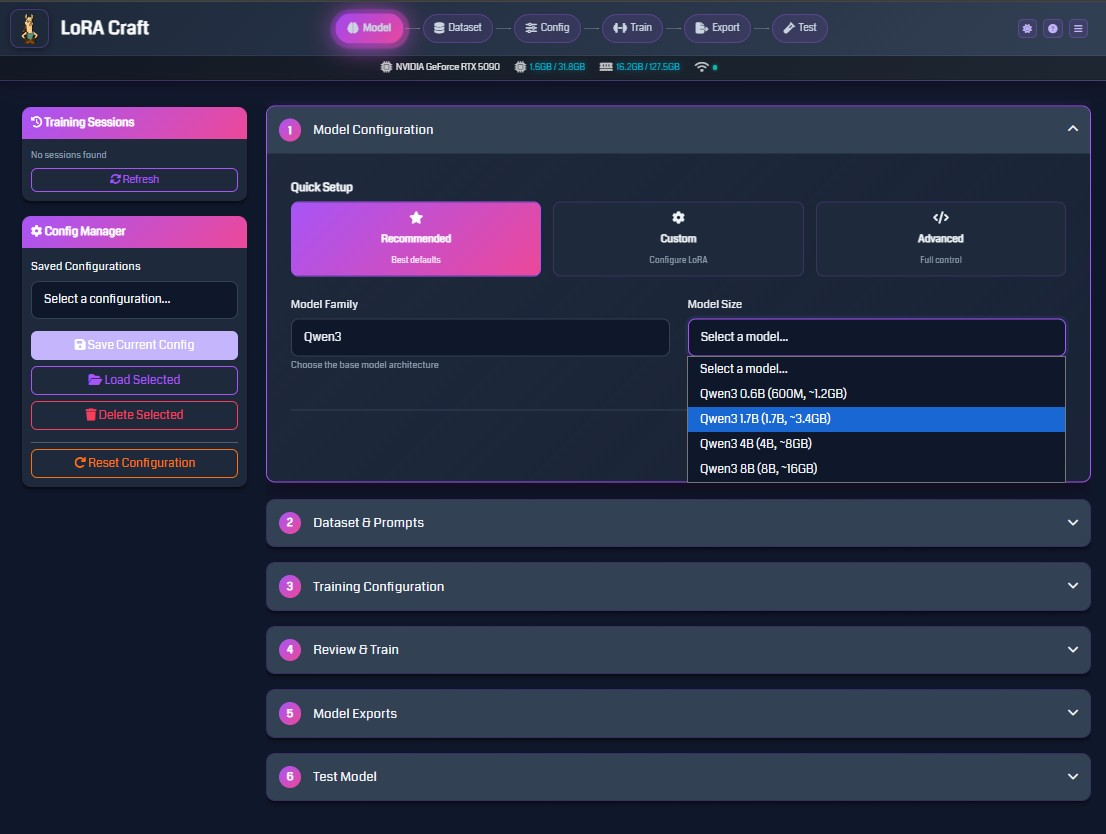
1. Select Your Model
Choose from Qwen, Llama, Mistral, and Phi models. Configure LoRA parameters or use recommended defaults.
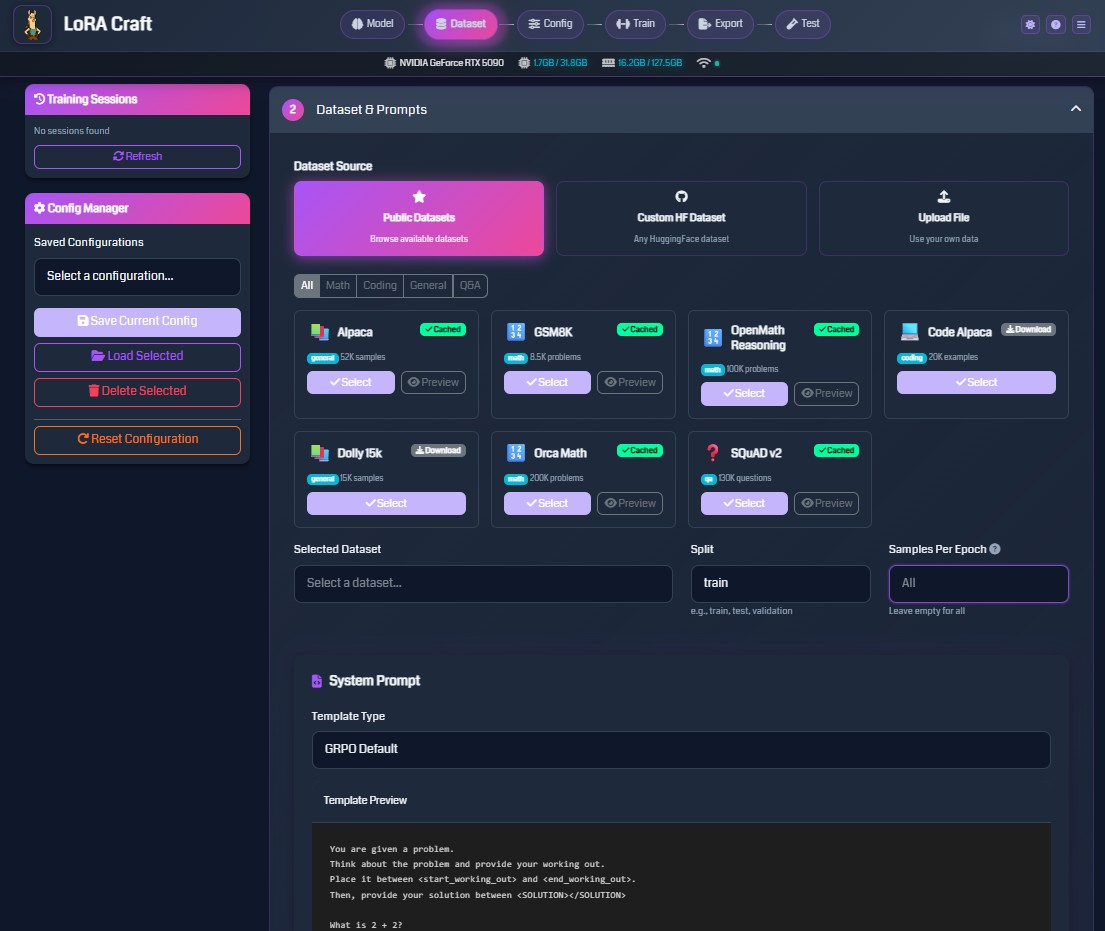
2. Choose Your Dataset
Browse curated datasets or upload your own. Auto-detects field mappings for instant configuration.
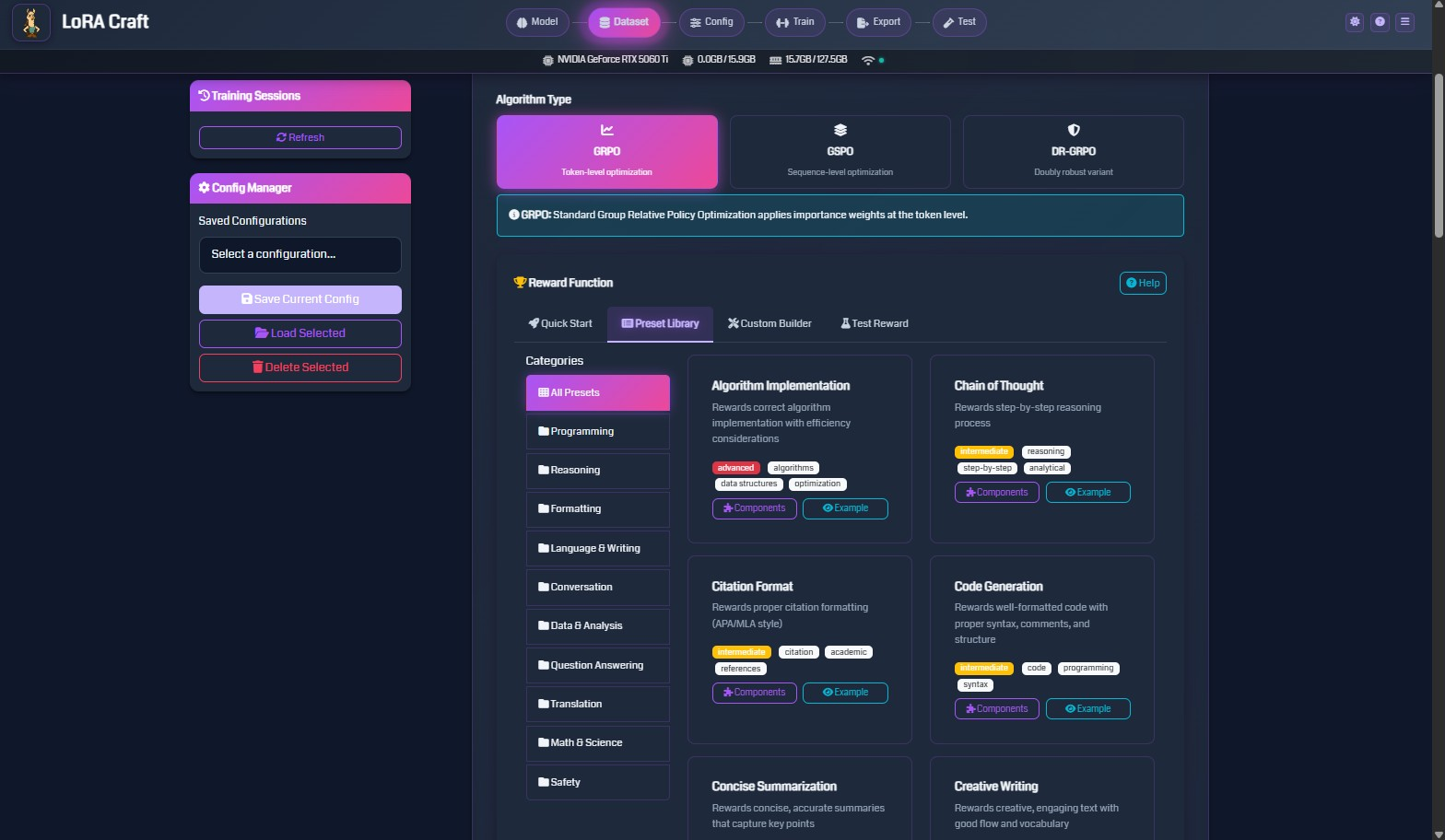
3. Pick a Reward Function
Select from categorized reward functions optimized for math, coding, reasoning, and creative tasks.
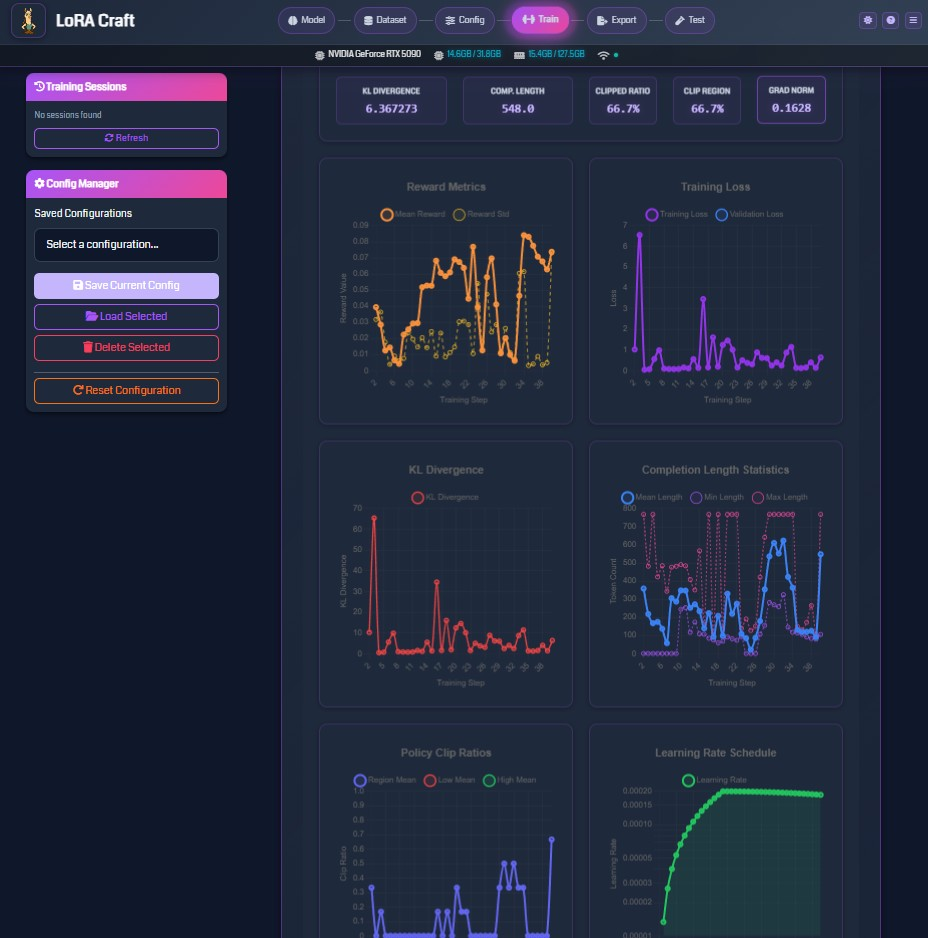
4. Monitor Training
Track real-time metrics with interactive charts. Watch rewards increase and loss decrease as your model learns.
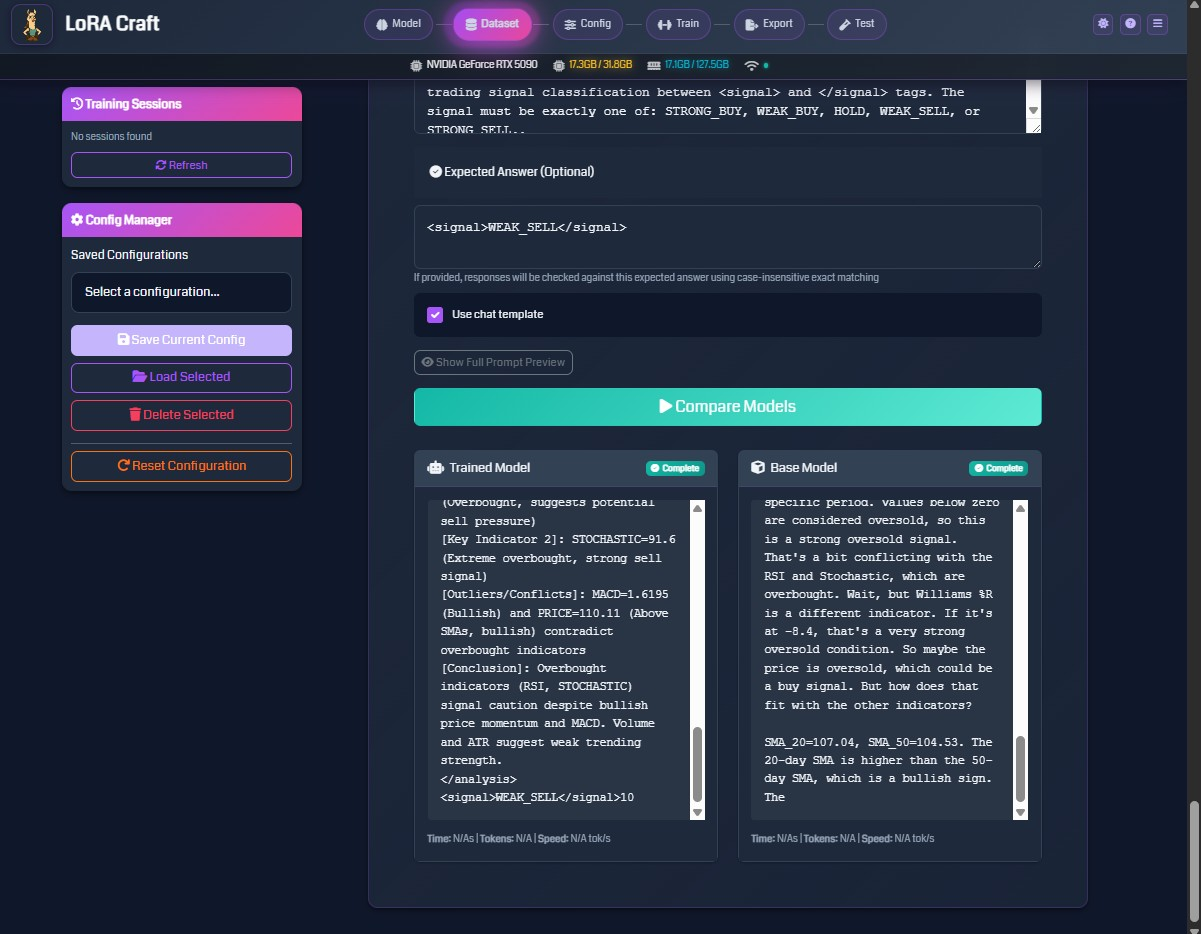
5. Test & Compare Models
Evaluate your fine-tuned models against base models with interactive testing, side-by-side comparison, batch testing, and reward function evaluation.
Popular Use Cases
∑ Math & Science
Train models to solve equations, prove theorems, and explain scientific concepts with step-by-step reasoning.
Learn more →‹/› Code Generation
Create coding assistants that generate clean, efficient code with proper documentation and error handling.
Learn more →? Question Answering
Build specialized Q&A systems for domains like medicine, law, or customer support with accurate, relevant answers.
Learn more →✎ Custom Tasks
Fine-tune for any task with custom reward functions: summarization, translation, creative writing, and more.
Learn more →What You Can Do
- Fine-tune for specific tasks: Math reasoning, code generation, question answering, instruction-following
- Use curated datasets: 7 pre-configured datasets including Alpaca, GSM8K, OpenMath, Code Alpaca, Dolly 15k, Orca Math, and SQuAD
- Upload custom data: Train on your own JSON, JSONL, CSV, or Parquet datasets
- Monitor in real-time: Track loss, rewards, KL divergence, and other metrics through WebSocket-based updates
- Test and compare models: Interactive evaluation interface with side-by-side comparisons and batch testing
- Export anywhere: Convert models to GGUF format for llama.cpp, Ollama, or LM Studio
- Save configurations: Reuse training setups for reproducibility across experiments
Powered by GRPO
LoRA Craft uses Group Relative Policy Optimization (GRPO), a reinforcement learning algorithm that teaches models to maximize rewards rather than just imitate examples.
How it works:
- Model generates multiple responses for each prompt
- Reward function scores each response based on your criteria
- Model learns to prefer high-reward responses
- Training continues until the model consistently produces quality outputs
This approach enables models to learn complex behaviors and improve beyond the quality of training data.
Ready to Get Started?
Start fine-tuning your first model in minutes
Choose Docker for the easiest setup with zero configuration, or install natively for maximum control. Both methods support full GPU acceleration.
Quick Start Guide Full DocumentationOpen Source & Community-Driven
LoRA Craft is MIT licensed and built with:
- Unsloth - Optimized training framework
- HuggingFace Transformers - Model library
- Qwen - High-performance language models (Documentation)
- Flask - Web framework